SQL INNER JOIN 操作
在本教程中,你将学习如何使用 SQL 内部联接从两个表中获取数据。
使用内部联接
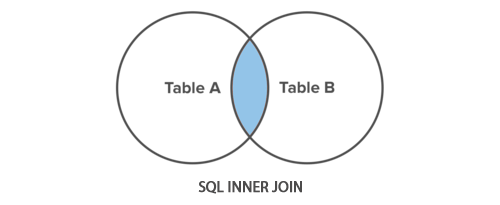
INNER JOIN 是最常见的联接类型。它仅返回两个连接表中具有匹配项的行。以下维恩图说明了内连接的工作原理。
为了便于理解,让我们看看以下 employees 和 departments 表。
Table: employees
+--------+--------------+------------+---------+
| emp_id | emp_name | hire_date | dept_id |
+--------+--------------+------------+---------+
| 1 | Ethan Hunt | 2001-05-01 | 4 |
| 2 | Tony Montana | 2002-07-15 | 1 |
| 3 | Sarah Connor | 2005-10-18 | 5 |
| 4 | Rick Deckard | 2007-01-03 | 3 |
| 5 | Martin Blank | 2008-06-24 | NULL |
+--------+--------------+------------+---------+
Table: departments
+---------+------------------+
| dept_id | dept_name |
+---------+------------------+
| 1 | Administration |
| 2 | Customer Service |
| 3 | Finance |
| 4 | Human Resources |
| 5 | Sales |
+---------+------------------+
现在,假设你需要仅检索分配到特定部门的员工的 ID,名称,雇用日期和部门名称。因为,在现实生活中,可能会有一些员工尚未分配到某个部门,例如 employees 表中的第五个员工“Martin Blank” 。但问题是,如何从同一 SQL 查询中的检索两个表中的数据? 好吧,让我们来看看。
如果你看到 employees 表,你会注意到它有一个名为 dept_id 的列,其中包含每个员工分配到的部门的 ID,employees 表的 dept_id 列是 departments 表的外键,以及因此,我们将使用此列作为这两个表之间的桥梁。
这是一个示例,通过使用公共 dept_id 列将 employees 和 departments 表连接在一起来检索员工的 ID,姓名,雇用日期及其部门。它排除了那些未被分配到任何部门的员工。
SELECT t1.emp_id, t1.emp_name, t1.hire_date, t2.dept_name
FROM employees AS t1 INNER JOIN departments AS t2
ON t1.dept_id = t2.dept_id ORDER BY emp_id;
提示: 连接表时,在每个列名前加上它所属的表的名称(例如 employees.dept_id , departments.dept_id 或者 t1.dept_id , t2.dept_id 如果你使用表别名的话),以避免在不同表中的列具有的情况下出现混淆和模糊列错误一样的名字。
注意: 为了节省时间,你可以在查询中使用表别名来代替键入长表名称。例如,你可以为 employees 表提供别名 - t1 ,然后使用 t1.emp_name 引用 emp_name 而不是使用 employees.emp_name。
引用其列执行上面的命令后,你得到如下结果集:
+ -------- + -------------- + ------------ + ------------ ----- +
| emp_id | emp_name | hire_date | dept_name |
+ -------- + -------------- + ------------ + ------------ ----- +
| 1 | Ethan Hunt | 2001-05-01 | 人力资源|
| 2 | 托尼蒙大拿| 2002-07-15 | 管理|
| 3 | 莎拉康纳| 2005-10-18 | 销售|
| 4 | Rick Deckard | 2007-01-03 | 财务|
+ -------- + -------------- + ------------ + ------------ ----- +
如你所见,结果集仅包含那些存在 dept_id 值的员工,该值也存在于 departments 表的 dept_id 列中。